JavaScript性能优化
PART 1
1、概述
- 内存管理
- 垃圾回收与常见GC算法
- V8引擎的垃圾回收
- Performance工具
- 代码优化实例
2、内存管理
- 内存:由可读写单元组成,表示一片可操作空间。
- 管理:人为的去操作一片空间的申请、使用和释放。
- 内存管理:开发者主动申请空间、使用空间、释放空间。
- 管理流程:申请-使用-释放
申请内存:let obj = {}
使用内存:obj.name = 'xxx'
释放内存:obj = null
3、JavaScript中的垃圾回收
JS引擎自动进行内存管理(垃圾回收)。
垃圾:不再被引用,不能从根上访问。
可达对象:引用,作用域链。
可达标准:能否找到。
JS中根:全局变量对象。
以图来说,垃圾即为入度为0的点。
4、GC算法介绍
垃圾:1、不再需要。2、不能访问。
常见GC算法:1、引用计数。2、标记清除。3、标记整理。4、分代回收
5、引用计数算法实现原理
设置引用计数器。引用关系改变则修改引用计数器。引用为0时则回收。
6、引用计数算法优缺点
优点:发现垃圾立即回收。最大限度减少程序暂停(时刻监控、引用改变则修改)。
缺点:无法回收循环引用对象。时间开销大。
7、标记清除算法实现原理
标记阶段:遍历所有对象标记对象(从global递归查找)。
清除阶段:遍历所有对象清除没有标记的对象,回收相应空间。将回收空间直接放在当前空闲链表上,后面程序可以直接在此申请空间使用。
8、标记清除算法优缺点
优点:只要在根(global)下不可达,就不需标记(函数局部空间变量与与global失去联系)。而在清除阶段就可回收。而引用计数是哪怕在根下不可达,但若在函数内有引用(循环引用)则不可回收。
缺点:空间碎片化(空闲链表中的空间不连续,所需大小不符会有碎片产生)。也不会立即回收垃圾。
9、标记整理算法实现原理
标记清除的增强,标记阶段与标记清除一致,清除阶段会先执行整理。移动对象位置,再批量回收(碎片少)。但和标记清除一样不会立即回收垃圾对象。
10、常见GC算法总结
引用计数:通过引用计数器来维护每个对象的引用数值,通过数值是否为0来判断对象是否为垃圾对象。
优点:可以即时回收垃圾对象,减少程序卡顿时间。
缺点:无法回收循环引用对象,资源消耗较大。
标记清除:分为两个阶段,第一阶段先遍历所有对象并给活动对象进行标记,第二阶段会清除所有未标记对象。
优点:可以回收循环引用的对象。
缺点:容易产生碎片化空间,浪费空间。不会立即回收垃圾对象。
标记整理:在标记阶段和标记清除一样,但在清除前会先进行空间的整理。
优点:在标记清除的基础上减少了碎片化空间。
缺点:不会立即回收垃圾对象。
PART 2
11、认识V8
V8是一款主流的JS执行引擎,采用即时编译(JIT),速度快。内存设限(64位1.5G,32位800M)。
12、V8垃圾回收策略
采用分代回收思想(将内存分为新生代、老生代),针对不同对象采用不同算法。
V8常用GC算法:1、分代回收。2、空间复制。3、标记清除。4、标记整理。5、标记增量。
13、V8如何回收新生代对象
V8中内存空间一分为二。小空间用于存储存活时间较短的新生代对象(32位中约为32M,64位中约为64M),如局部变量等。

新生代回收实现(回收过程采用空间复制+标记整理算法):新生代内存区分为两个等大小空间。活动对象存储于“From空间”。当From空间大小超过一定限制时触发GC,进行标记整理后拷贝到“To空间”。当From与To交换空间完成后释放(使用空间为From,空闲空间为To并在标记整理后交换空间及状态)。
回收细节:拷贝过程中可能出现晋升。即,将新生代对象移动到老生代中。一轮GC后还存活的新生代需要晋升。To空间使用率超25%需要晋升。
14、V8如何回收老生代对象
老生代对象就是指存活时间较长的对象(全局对象或闭包中的一些数据等),存放在V8内存空间图示右侧的老生代区,在64位操作系统中大小约为1.4G,32位操作系统中约为700M。
老生代对象的回收主要采用标记清除、标记整理、增量标记算法,在触发GC时首先使用标记清除完成垃圾空间的回收,若在新生代晋升时老生代空间不足,则采用标记整理进行空间优化。除此外还采用增量标记进行优化。
为什么不沿用新生代的算法呢,因为与新生代区垃圾回收算法对比,新生代空间较小,可以使用复制算法来进行空间换时间,但老生代空间较大,已经不适合复制算法了。
另外,老生代还使用了增量标记的方法来进行优化:
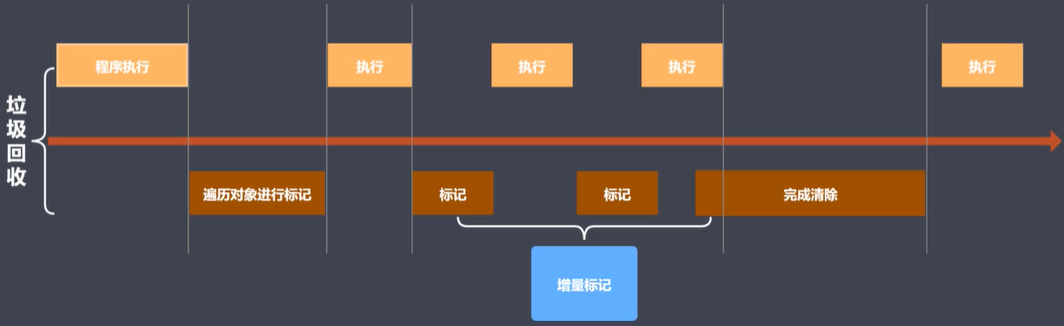
在上图中,上面部分是程序的执行,下面部分是垃圾的回收,垃圾回收与程序的执行是互相阻塞的,而从图中可以看出,程序执行与垃圾回收都不是一次性连续完成的,而是间断地渐进式完成的。这是因为老生代空间较大,若一次性连续完成则可能会发生较长停顿,影响用户体验,而采用这种增量标记的方式可以提升程序执行的连贯性(不会长时间阻塞),保持良好的用户体验。就像DMA与CPU交替访问内存一样,可以在完成各自的功能下不会太过影响体验。
15、V8垃圾回收总结
- V8是一款主流的JavaScript执行引擎
- V8内存设置上限(64位:1.5G,32位:800M。原因:浏览器足够使用,垃圾回收机制所花时间不能太长。)
- V8内存分为新生代和老生代,用基于分代回收思想实现垃圾回收
- 新生代使用复制、标记整理算法。老生代使用标记清除、标记整理、增量标记算法
16、Performance工具介绍
GC的目的就是为了实现内存空间的良性循环,而良性循环的基石就是合理使用,Performance就提供了多种监控方式,让我们对内存的变化有实时的监控。
使用Performance也很简单,只需要打开浏览器并输入目标网址,再进入开发人员工具面板(浏览器下按F12),选择性能(Performance)进入Performance工具。然后开启录制(Record)功能,再访问具体的页面并执行用户行为,一段时间后停止(Stop)录制,就可以得到一份报告,最后再来分析报告界面中记录的相关内存信息(记得需要勾选上内存(Memory)选项才能看到内存相关信息)。
17、内存问题的体现
- 页面出现延迟加载或经常性暂停(GC频繁进行垃圾回收)
- 页面持续性出现糟糕的性能(存在内存膨胀,即申请的内存空间超过了设备本身能提供的大小)
- 页面的性能随时间延长越来越差(存在内存泄漏)
18、监控内存的几种方式
界定内存问题的标准:
- 内存泄漏:内存使用持续升高,没有下降趋势
- 内存膨胀:当前应用程序为了达到最优的效果,可能需要很大内存空间而设备不能提供。若在多数设备上运行时都存在糟糕的性能体验,则说明程序本身是有问题的。
- 频繁垃圾回收:通过内存变化图进行分析
监控内存的几种方式:
- 浏览器任务管理器
- Timeline时序图记录
- 堆快照查找分离DOM,分离DOM的存在也就是一种内存上的泄漏
- 判断是否存在频繁的垃圾回收
19、任务管理器监控内存
首先,进入浏览器后通过Shift+Esc来打开任务管理器(也可在浏览器右上角下拉选项中找到更多工具,从其中找到任务管理器):
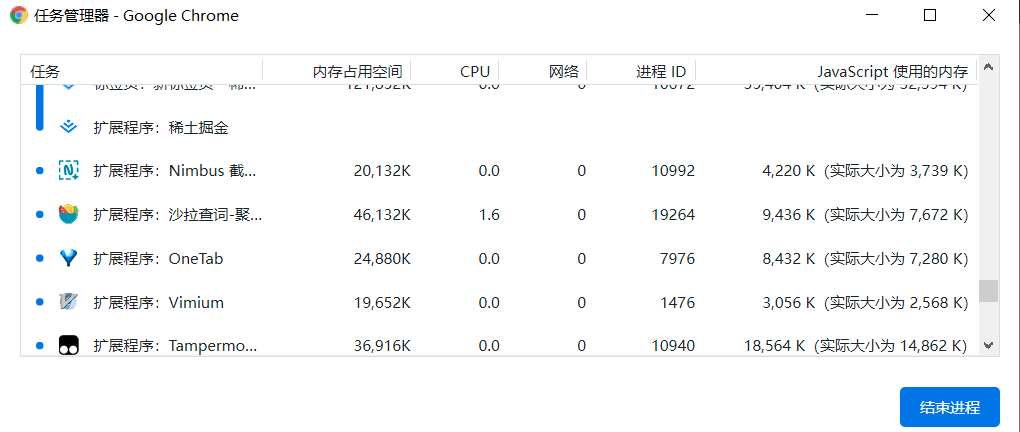
打开任务管理器后找到具体的web页面,先来关注“内存占用空间”列,此列表示的是原生内存,即DOM节点所占的内存,一般此列都是不变的,若发生频繁变化,说明当前页面存在频繁的DOM操作。之后查看“JavaScript使用的内存”列(若没有相关列,在任务管理器界面右键,点击“JavaScript使用的内存”打开相关列即可),该列表示JS中的堆,而其中小括号中的数值表示的是所有可达对象正在使用的内存大小,若小括号中的数值增大则表示在该页面中正在创建新对象或已有对象在不断增长。该列中我们需要关注小括号里的数值,若小括号里的数值一直增加,而没有变小的趋势,就意味着内存是一直增大而没有GC消耗。
20、Timeline记录内存
之前我们介绍了任务管理器,他可以监控当前脚本中内存的变化,但更多的只是判断当前脚本中的内存是否存在问题,而不能定位到具体产生问题的地方。而Timeline则可以记录内存的变化,从而更加精确定位到当前内存中的问题与代码中哪里有关。
首先,先按照之前”16、Performance工具介绍“里描述的打开Performance工具,并点击进行录制,再触发想要测试的相关代码,之后停止录制,查看分析报告,勾选“内存”查看内存信息,选中”JS堆“查看相关堆内的使用情况,拉动对应的Timeline到出现问题的位置,从而定位内存出现问题时所运行的代码。
21、堆快照查找分离DOM
堆快照的工作原理就是找到当前的JS堆,然后对他进行快照留存,有了照片后就可以看到里面的所有信息。
什么是分离DOM(Detached DOM)
界面元素都是一个个DOM节点,本应该存活在DOM树上,不过对于DOM节点,会有两种特殊形态:垃圾DOM以及分离DOM。当一个节点从DOM树上脱离,并且在JS代码中也没有引用就成为了垃圾DOM。而如果当前的DOM节点只是从当前的DOM树上脱离,但在JS代码中还有引用,就称为分离DOM。这种分离DOM在界面上是看不见的,但在内存里却是占据着空间,所以在这种情况下就是一种内存泄漏,而我们则可以通过堆快照的功能,去把他们都找出来,之后就可以在代码里针对他们进行清除,让内存得以释放,让脚本执行更加迅速。
如何使用堆快照检查分离DOM
打开浏览器,打开调试工具,选择“内存(Memory)”选项,选择“堆快照(Heap SnapShot)”后点击“获取快照(Take Snapshot)”即可得到当前堆的快照,过一会儿就可以看到当前活动对象的具体展示了。之后可以在上方看到一个类筛选器(Class filter)输入框,可以输入“detached”(分离)筛选分离DOM,但此时一般是没有的。然后我们就可以执行可能会产生分离DOM的代码,再执行上面的操作获取堆快照,并进行相关筛选,最后即可得到代码中产生的相关分离DOM。而对于这些分离DOM,我们如果确认在后期不会使用他们,就可以把相关代码中将这些DOM置空即可。
22、判断是否存在频繁GC
因为GC工作时应用程序是停止的,所以频繁且过长的GC会导致应用假死而用户则会在使用过程中感知到应用的卡顿。
确定频繁的垃圾回收
- 可以通过Timeline中有无出现频繁的上升下降判断是否有频繁的GC,之后我们就可以定位到相应的时间节点,查看是什么操作导致这种现象产生,接着在代码中进行相关处理来解决问题。
- 当任务管理器中数据出现频繁的增加减小时则有可能出现频繁的GC,一般情况,当我们的界面渲染完成之后,如果没有其他额外的操作,无论是DOM节点内存,还是JS内存来讲都是基本不变化的数值,但如果出现频繁的GC时,则有可能会出现瞬间增大,瞬间又减小的情况。
频繁的垃圾回收给外部带来的明显现象就是页面出现“卡顿”,而对于内部来说则有可能是当前代码中存在对内存操作不当的行为,让GC不断工作去回收相应空间。
23、Performance总结
- Performance是谷歌浏览器所内置的一个工具。通过Performance工具的使用,我们可以对内存做一个适当的监控。
- 而对于内存问题,又可以分为“内存泄漏”、“内存膨胀”、“频繁的GC操作”等。
- 对于这些问题我们则可以使用Performance中的时序图来监控内存变化从而定位到有问题的时间节点所做的操作,再定位到代码当中的内容。
- 除此之外,我们还可用任务管理器来监控内存变化,对于任务管理器,主要功能还是监控DOM节点所占内存以及JS堆所占内存的变化,若这些数值持续增加,我们就需要考虑在代码中是否存在不妥的地方。
- 之后,还有堆快照可以帮我们查找分离DOM,分离DOM必然存在内存泄漏的现象,如果这样的代码越来越多,我们的程序就会随着使用时间的增长而表现出糟糕的情况。
24、V8引擎执行流程
V8引擎本身也是一个应用程序,本质上就是JS的执行环境。只考虑浏览器平台,不考虑NodeJS平台下,V8引擎可以看做是浏览器的组成部分,用来解析及编译所书写的JS代码,在其内部,同样也存在着很多子模块。
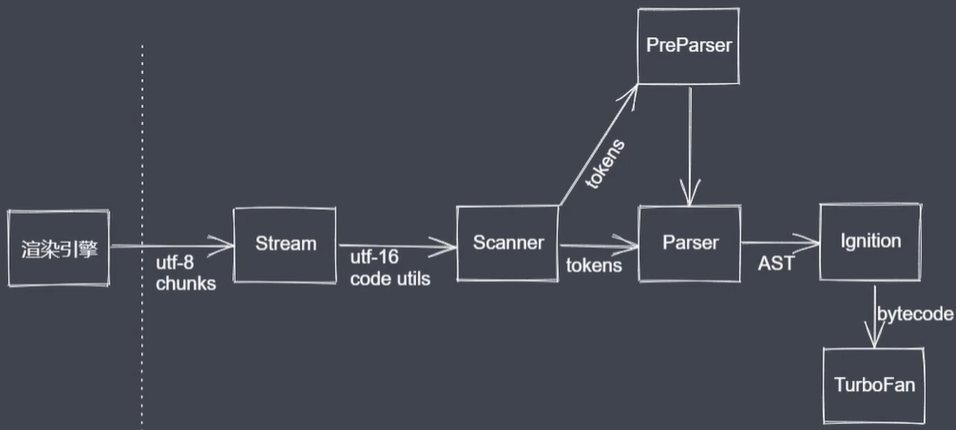
V8引擎其实只是浏览器渲染引擎里JS执行代码的组成部分。
Scanner是一个扫描器,对纯文本的JS代码进行词法分析来把代码分析成一个个token(在语法上不能再分割的最小单位),有可能是单个字符,也有可能是一段字符串或数字等。
Parser是一个解析器,解析的过程就是一个语法分析的过程,他会去把词法分析结果中的token转换为抽象语法数AST(Abstract Syntax Tree),同时,也会在语法分析的过程中进行语法校验。
Parser的解析有两种,一种就是一般的全量解析Parser,此外,还有预解析PreParser。预解析可以跳过未被使用的代码,创建无变量引用和声明的scopes(注意预解析就确定scope作用域及作用域链)但不生成AST,并能依据规范抛出特定错误且有比全量解析更快的速度。
而对于全量解析,他会解析被使用的代码并生成AST,构建具体scopes信息,变量引用、声明等(对应执行上下文的创建)且会抛出所有的语法错误。
// 声明时未调用,因此会被认为是不被执行的代码,进行预解析
function foo() {
console.log('foo');
}
// 声明时未调用,因此会被认为是不被执行的代码,进行预解析
function fun() {}
// 函数立即执行,只进行一次全量解析
(function bar() {})();
// 执行foo,还需要重新对foo函数进行全量解析,此时foo函数被解析了两次
foo();注意嵌套层级太深时就会导致多次的解析操作,因此书写代码时要去减少不必要的函数嵌套。
Igition是V8提供的一个解释器,他可以把之前生成的AST转为字节码basecode,同时还会去收集下一个编译阶段所需要的信息(也可以把这个过程看做预编译的过程)。注意,基于性能的考虑,不会把预编译和编译区分得很明显,因为有些代码可以在预编译阶段就直接执行。
TurboFan是V8引擎提供的编译器模块,他会利用上一个阶段所收集到的信息,再把字节码转换为具体的汇编代码,之后就开始执行代码了,也即后续要讲到的堆栈执行过程。
PART 3
25、堆栈处理
堆栈处理,即浏览器在内存层面所做的一些处理。了解堆栈处理可以让我们从本质上分析一段代码的执行过程,或者分析代码执行时的性能问题。
JS代码在执行时需要有一个执行环境比如常见的V8,而代码最终会被转为可以被识别的机器码在执行环境栈(ECStack,execution context stack)中执行。浏览器在渲染界面时,会在计算机的内存中开辟一片内存空间用来执行JS代码,其中栈内存指的就是执行环境栈。不同的代码间又需要保持相互的独立,于是有了不同的执行上下文,每个执行上下文中的代码在需要的时候进栈操作即可。但无论如何操作,全局的执行上下文一定是存在的,即在栈底永远会有一个全局执行上下文EC(G)。另外全局所有的变量声明都会存放在EC(G)对应的全局变量对象VO(G)中(在代码执行前EC(G)中变量声明就会放在VO(G)中,变量提升)。总而言之,代码的执行步骤,针对全局来说,就需要编译(包含词法分析,语法分析等过程)以及代码执行,另外为了便于分析,我们在中间人为加一个变量提升过程。
(注意为了更好演示执行机制,声明变量时会刻意使用var关键字。)
先来看一段代码:
var x = 100;
var y = x;
y = 200;
console.log(x);这段代码会在全局的执行上下文EC(G)中并进执行环境栈ECStack执行。
在运行var x = 100时,会先创建一个值100,由于100是一个基本数据类型,所以会直接存放在栈区。之后会声明一个变量x存放在EC(G)的VO(G)中(注意变量提升),最后再建立变量与值之间的联系。
第二行中会再在VO(G)中创建一个变量y并与之前的100之间建立联系。
然后第三行中会再创建一个200,并与之前的y建立联系(基本数据类型按值访问),注意这里并没有影响x。
在讲第4行之前还需要了解一个叫全局对象GO的对象,他并不是VO(G),但他是一个对象,因此也会有一个内存的空间地址以及对应的内存空间,又因为有地址故可以对其进行访问。JS会在VO(G)中准备一个变量“window”,该变量中就存放GO对象的地址(使用时window可以省略),通过该变量就可以找到GO对象以及里面的类似console.log,setTimeOut等函数。
而第四行就是调用了GO对象中的console.log函数对x值进行输出,注意用window.console.log(x)也可,只不过一般都会省略window。
总结:1、基本数据类型是按值进行操作的。2、基本数据类型存放在栈区。3、无论是栈内存还是后续讲到的堆内存都属于计算机内存。4、全局对象GO,他是JS或说浏览器底层为我们准备好的,我们可以直接调用里面的内容。
推荐参考链接:「前端进阶」JS中的栈内存堆内存 - 掘金 (juejin.cn)
26、引用类型堆栈处理
先来看一段代码:
var obj1 = { x: 100 }
var obj2 = obj1;
obj2['x'] = 200;
console.log(obj1.x); // 200首先,和之前提到的一样,会有一个执行环境栈ECStack,然后这部分代码会在全局执行上下文EC(G)中并进ECStack中执行。
而在EC(G)中会有对应的VO(G),里面会存放对应的变量:obj1与obj2(注意变量提升)。
之后因{ x: 100 }是一个对象,所以会先在堆内存中开辟一片空间,并把他存放在该堆内存空间中,并把其对应的内存地址与obj1建立联系。
代码第二行会把obj1中的内存地址再与obj2建立联系
代码第三行中会通过对象属性访问的方式通过内存地址找到堆内存空间中对应对象的属性x的值并把他修改为200。
最后一行会先找到obj1中保存的内存地址对应的内存空间并获取该内存空间中对应对象的x属性值再用GO中的console.log函数对他进行输出。
若我们对上面的代码进行一些修改:
var obj1 = { x: 100 }
var obj2 = obj1;
obj2 = { name: 'george' }
console.log(obj1.x); // 100运行后我们会发现obj1.x的值并不会发生改变。这里需要注意的就是在代码第三行中,会重新在堆内存中开辟一片空间,并把对象{ name: ‘george’ }中的内容放进去,最后再把新开辟的地址空间重新与obj2建立联系,所以obj1中保存的地址及其空间中的对应内容并没有发生改变。
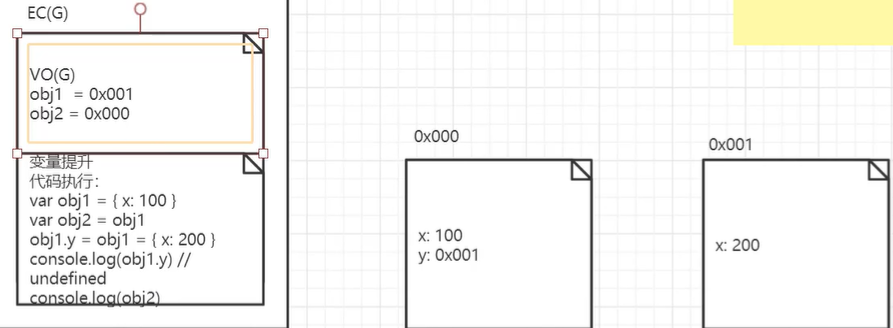
最后再来看:
var obj1 = { x: 100 }
var obj2 = obj1;
obj1.y = obj1 = { x: 200 }
console.log(obj1.y); // undefined
console.log(obj2); // {x: 100, y: {x: 200}}
console.log(obj1); // {x: 200}上面代码与之前代码的最主要区别还是在第三行。讲解之前,我们还必须先来介绍一下有关的运算符优先级,注意在obj1.y = obj1中,对象的“.”操作优先级是大于“=”的,所以会先执行“obj1.y”,之后再执行“= obj1”。之前我们讲过,obj1与obj2中保存的堆内存地址是一致的,所以在第三行中执行obj1.y与obj2.y的效果是一样的,都会找到对应地址的内存空间,并找到对应的y属性(此时y的值为undefined)。然后y与obj1建立联系(即y的值即为obj1中的值,都为相同的堆内存地址),之后还会新开辟一块堆内存空间,存放{ x: 200 }内容,并把对应的地址再与y属性(obj1)建立联系。注意此时y中的值即为obj1对应的值,且之后obj1中保存的地址变为了新开辟的内存空间的地址。所以最后的obj1中保存内存地址对应的内容为{x: 200},且obj2中保存内存地址对应的内容为{x: 100, y: {x: 200}}。
27、函数堆栈处理
看一段代码:
var arr = ['czs', 'george'];
function foo(obj){
obj[0] = 'hello';
obj = ['world'];
obj[1] = 'javascript';
console.log(obj);
}
foo(arr); // ['world', 'javascript']
console.log(arr); // ['hello', 'george']注意,创建函数与创建引用类型的变量类似,函数名此时就可以看做是一个变量名保存在VO中。并且与创建对象一样会单独开辟一片堆内存用于存放函数体(字符串形式代码),而当前内存地址也会有一个16进制数值地址指向函数体,创建该函数之后就会将其函数体的内存地址存放在栈区与对应的函数名进行关联。且创建函数的时候,他的作用域[[scope]](创建函数时所在的执行上下文,如上面的foo函数就是EC(G))就已经确定了。
首先,会有一个执行环境栈ECS,栈底会有一个全局执行上下文EC(G),里面会有一个全局变量对象VO(G),保存arr与foo,注意此时函数体已在堆内存中,且其所在的内存空间地址已经与foo进行关联了(在变量提升阶段完成)。
在变量提升都完成之后,就开始进入代码执行阶段。在第一行代码中,因数组也是一个对象,所以同样需要新开辟一片堆内存空间存放[‘czs’, ‘george’],并将该内存空间的地址放在栈中并与VO(G)中的arr建立联系。
之后就是foo函数的声明了,而这些内容在变量的提升阶段已经基本上分析完了,可以直接看下面的函数执行。函数执行的目的就是为了将函数所对应的堆内存里的字符串形式代码进行执行。代码在执行时就需要一个环境,所以函数在执行时就会生成一个新的执行上下文来管理函数体中的代码,在此即为EC(FOO),也即foo函数的私有上下文。之后EC(FOO)进栈,注意在函数私有执行上下文进栈后,存放当前执行上下文变量的对象不是VO而是叫AO(因为变量对象VO在执行上下文进入执行栈时,就变成了活动对象AO,可以将AO看做是VO在函数私有执行上下文的不同表示)。
函数在执行时所做的事大概为:1、确定作用域链(当前执行上下文,上级执行上下文)。2、确定this(在此为window)。3、初始化arguments对象(这里没有)。4、形参赋值(在上面代码中foo函数执行时传入实参arr,故在EC(FOO)的AO中会有一个形参变量obj与arr保存的地址建立联系。)。5、变量提升(foo函数中无函数声明与var声明,故没有)。6、开始执行代码。
接下来我们看函数执行的代码,第一句中,找到obj对应的堆内存空间并将0号元素’czs’改为’hello’,注意obj为形参,在传进实参arr时obj与arr对应的堆内存空间是同一片(引用传递),故执行后obj与arr对应内存空间由[‘czs’, ‘george’]变为了[‘hello’, ‘george’]。之后第二句,又新开辟了一片堆内存空间存放[‘world’],并把其空间地址与obj建立联系。之后第三句中,找到obj对应的内存空间中1号元素并赋值为’javascript’,注意在第二步中obj已和堆内存中内容为[‘world’]的内存空间建立联系,故之后该内存空间保存了[‘world’, ‘javascript’]。最后第四句中将obj中保存的地址对应的内存空间[‘world’, ‘javascript’]内容进行输出。
在函数完成执行后,会将EC(FOO)进行出栈,然后进入EC(G)中继续执行最后一行代码,输出arr中对应地址的内存空间内容[‘hello’, ‘george’]完成代码的执行。
总结:
函数在创建时,可以将函数名看作是变量,存放在VO当中,同时他的值就是当前函数对应的内存地址。注意函数本身也是一个对象,创建时也会有一个内存地址,该空间内存放的就是字符串形式的函数体代码。函数在执行时会形成一个全新的私有上下文,里面有一个AO用于管理这个上下文中的变量(相当于函数私有上下文中的VO)。
函数执行的步骤:1、确定作用域链(当前与上级作用域所在的执行上下文)。2、确定this。3、初始化arguments(对象)。4、形参赋值(相当于变量声明,将其放与AO再赋值)。5、变量提升。6、代码执行。注意函数执行完后就会对当前函数的EC进行出栈。
28、闭包堆栈处理
先来看一段代码:
var a = 1;
function foo() {
var b = 2;
return function(c) {
console.log(c + b++)
}
}
var f = foo()
f(5)
f(10)首先,经过之前的介绍,我们知道在代码执行时会先有一个执行环境栈ECStack,底层会有一个全局执行上下文EC(G),里面有一个全局变量对象VO(G)。然后经过变量提升会先把a,foo,f放进VO(G)中,且还会开辟一片堆内存空间存放foo的函数体并将该内存空间地址保存在栈空间中与foo建立联系(注意此时函数当前所在的作用域[[scope]]在此处即EC(G)已经确定)。之后进入代码的执行阶段,在代码第一句中会创建1并放在栈中,与VO(G)中的a建立联系。之后是函数的声明,基本上已经在变量提升阶段完成。再接着是foo函数的执行,并将返回值与f建立联系。
之后因为需要调用foo函数,所以会有一个函数的私有执行上下文EC(FOO)并进执行栈,在EC(FOO)中会有一个AO(FOO)保存当前函数私有执行上下文的相关变量。接着就是函数的执行阶段,首先是确定作用域链,也即确定当前的执行上下文EC(FOO)与EC(G),确定this,确定arguments,形参的赋值,变量提升(把b放在AO中,注意定义函数会存在函数体的提升,定义匿名函数时也会将匿名函数定义变量提升,但赋值部分不会提升。故在经过变量提升后会先在堆内存中开辟一片空间存放匿名函数的函数体,并在栈中保存对应的地址,但没有与其他变量建立联系(赋值)),之后进行代码执行。执行时先在栈中创建2并与b建立联系,之后就将栈中的匿名函数对应地址返回,与EC(G)中VO的f建立联系。
此处再加入一个知识点:被捕获变量,简言之就是出现在函数声明但在函数返回后依旧有被未执行完成的作用域(函数或类)引用的变量。被捕获变量在函数执行完成后并不会进行释放,而是会在堆中,用一个特殊的对象(Scoop)保存(注意返回的函数地址也相当于被引用,保存在堆中):
参考链接:传送门
function testCatch1 () {
let catch1 = 1;
var catch2 = 'str';
const catch3 = true;
let catch4 = {a: 1};
return function () {
console.log(catch1, catch2, catch3, catch4)
}
}
console.dir(testCatch1())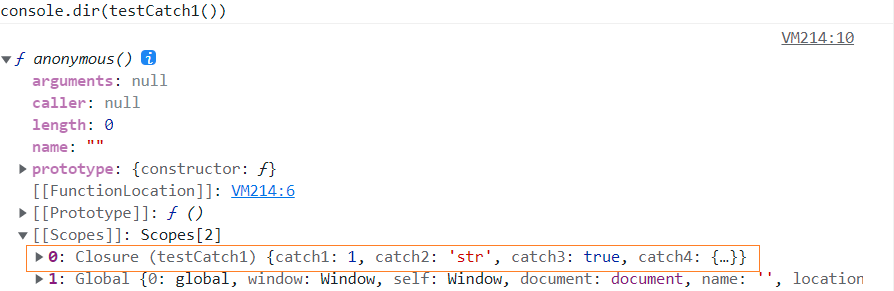
在foo函数执行完成后本应该将EC(FOO)出栈并将其的内容进行释放,但因EC(FOO)执行上下文当中引用的一个堆内存空间(foo函数返回的函数地址对应的空间,其中还包括被捕获变量b)还被EC(G)中的变量f所引用,故foo()调用时所创建的执行上下文还不能立即被释放,这也就形成了所谓的闭包现象。在此给出一个闭包的简单定义:闭包是一种通过私有上下文来保护其中变量的机制。也可以认为当我们创建的某一个执行上下文不被释放的时候就行成了闭包。而闭包的作用就是为了保护、保存数据。
之后继续执行f(5),因为这里调用了函数,也即f中保存的foo返回的函数,所以还会先确定作用域链(当前作用域EC(F)以及上一层作用域EC(FOO)),确定this,确定arguments,形参赋值(在新的函数EC的AO中有形参c,对应值为传进来的5),变量提升,在进行执行。又因执行时在当前的作用域没有找到b所以到上一级执行上下文,也即EC(FOO)中找,找到后继续执行代码,最后输出7,并将b的值加1。
然后因f(5)对应的EC中内容没有被其他的EC引用,所以此处需要出栈并回收对应的内存。最后执行f(10)的过程与f(5)类似(注意f(10)对应的EC与f(5)不同),最后输出13。
总结:
闭包是一种机制,能保护当前上下文中的变量与其他的上下文中变量互不干扰,若当前上下文中的数据被当前上下文以外的上下文中的变量所引用(被捕获变量),这个数据就会被保存下来。函数调用形成了一个全新的私有上下文,在函数调用之后当前上下文不被释放就是闭包(临时不被释放)。
我对闭包的理解:创建一个新的执行上下文(保护)并把其中被全局变量,函数,类(不同上下文)中引用的变量存进堆空间中(保存)。
29、闭包与垃圾回收
老规矩,先来看一段代码:
let a = 10
function foo(a) {
return function(b) {
console.log(b + (++a));
}
}
let fn = foo(10);
fn(5); //16
foo(6)(7); //14
fn(20); //32
console.log(a); //10首先就是EC(G)进栈执行,经变量提升后VO(G)中有a,foo以及fn,且foo与堆内存中的相关函数体关联(对应的作用域[[scope]]为EC(G))。之后代码执行,先在栈中创建一个常量10并与VO(G)中的a关联,之后是函数的声明,这在变量提升时已经基本完成,再然后就是foo函数的执行了。
foo函数的执行代表会有新的EC入栈,并且还与之前讲步骤的一样,要经过确定作用域链(这里是EC(FOO)与EC(G)),确定this,确定arguments,形参赋值(AO中会有变量a与栈中的10建立联系),变量提升(代码中有匿名函数,会和上一节讲的一样,在变量提升时就会开辟一片堆内存空间并将该内存空间的地址存与栈中),最后执行代码。执行时会将保存在栈中的匿名函数的地址返回,并与EC(G)中VO(G)的fn建立联系。其中要被返回的匿名函数地址与被匿名函数捕获的变量a都会存在堆内存中。
之后第9行中执行fn(5),函数执行,新的EC入栈,确定作用域链(EC(FN)与EC(FOO)),确定this,确定arguments,形参赋值(对应的AO中有变量b,值为5),变量提升,最后进行代码执行。代码执行时注意在当前的EC(FN)中是没有变量a的,所以要沿着作用域链找到上一层的EC(FOO)最后找到被存在堆中的变量a(值为在代码8行中传入的10),将a自增1,与AO中的b相加再输出对应的值,即5+10+1=16。注意执行结束后因其EC中的变量都没被引用所以在EC出栈后其对应的内存空间就会被释放。
第10行中的操作是8行与9行代码的整合,只不过没有和代码8行中的一样在VO(G)中创建变量fn引用foo返回的匿名函数,故在执行完成之后就会被出栈释放,其执行过程和第8行9行代码执行时的过程是类似的,不再赘述。
到了第11行,第11行与第9行的区别就只有传进来的实参不一样而已,不过要注意一个小细节就是在第9行代码执行后,EC(FOO)里保存在AO中的a已经自增为11了,故在第11行会输出32,即20+11+1(a还需要自增1)。这里需要注意,虽然第11行与第9行代码的形式是一样的,但其创建的EC是不一样的。
最后一行中,输出a的值,需要注意的就是这里的a是在EC(G)中的a而不是EC(FOO)中的a,所以是10而不是12。
注意:浏览器都有垃圾回收(GC)机制。在堆中若当前堆内存被引用,就不能被释放,不过如果我们确认后续不再使用这个内存里的数据,也可以主动置空,然后浏览器就会对其进行回收。在栈中若当前上下文中有内容被其他上下文变量所占用就无法被释放(闭包)。
30、循环添加事件的实现
在工作中,我们可能会出现一种需求,就是给多个控件去循环添加事件:
// 若在页面中有多个button,可以通过querySelectAll去获取所有button
// 注意获取到的NodeList只是一个伪数组,不能用数组的一些方法
var buttons = document.querySelectorAll('button');
// 先来一段有问题的代码
for (var i = 0; i < buttons.length; i++){
buttons[i].addEventListener('click', function(){
console.log(`当前索引值:${i}`);
})
}
// 这时若回到页面中去点击任意按钮,都会显示:当前索引值:Buttons.length + 1
// 此时我们应该都可以分析清楚原因了,不就是因为这里的i都是在EC(G)中的i吗
// 清楚了原因后自然可以想到用立即执行函数去构造闭包来创建新的EC去保存不同的i
for (var i = 0; i < buttons.length; i++){
buttons[i].addEventListener('click', (function(i){
return function(){
console.log(`当前索引值:${i}`);
}
})(i))
}
// 还有用IIFE立即执行函数构造闭包的不同方式
for (var i = 0; i < buttons.length; i++){
(function(i){
buttons[i].addEventListener('click', function(){
console.log(`当前索引值:${i}`);
})
})(i)
}
// 而在ES2015中还提供了let关键字,可用块级作用域来产生独立的上下文,也类似闭包的思想
for (let i = 0; i < buttons.length; i++){
buttons[i].addEventListener('click', function(){
console.log(`当前索引值:${i}`);
})
}
// 还可以用添加自定义属性的方式来实现要求
for (var i = 0; i < buttons.length; i++){
buttons[i].myIndex = i;
buttons[i].addEventListener('click', function(){
console.log(`当前索引值:${this.myIndex}`);
})
}需要注意的是,因为在闭包中(使用let的情况也相同),立即执行函数IIFE(在let中是块级作用域)的EC中因其中的变量i被其中的匿名函数引用,而匿名函数又因被设置为按钮点击事件监听函数(即在存储按钮对象对应的堆空间中被引用)其对应堆空间也不能被释放。所以IIFE(块级作用域)中的EC相关被引用的内容会保存在堆内存空间得不到释放,这就相当于造成了一定的空间浪费,也即内存泄漏。所以若我们之后不再需要用相关的按钮监听事件时,注意把用querySelectAll获取的各个button都置为null。
并且在最后一种方法中,我们仅仅只是在按钮对象所在的堆空间中多开辟了一点空间存储了一个变量(属性),所以在空间的利用率上还会比用闭包更好一些。
虽然在内存的使用上可能会不友好一些,但闭包还是一种在JS中非常优秀的机制,非常便于我们去实现一些高阶的应用。不过如果有其他替代方案,我们也可用非闭包方式来实现某些需求。
31、事件委托实现
先来看具体代码实现:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>事件委托实现</title>
</head>
<body>
<button index="1">button1</button>
<button index="2">button2</button>
<button index="3">button3</button>
</body>
<script>
document.body.addEventListener('click', function(event){
var target = event.target,
targetDom = target.tagName
if(targetDom === 'BUTTON'){
var index = target.getAttribute('index')
console.log(`当前点击的是第${index}个`)
}
})
</script>
</html>可以看到采用事件委托的形式来实现循环添加事件相同效果时,根本都不需要保存在上一节中用querySelectAll来获取的对应元素节点,所以可以节省大量堆内存空间。并且只需要保存一份匿名函数对应的堆内存空间,且其中的操作也不过是对象数据的存取以及访问的操作,无非是作用域查找的深还是浅的关系。所以用事件委托的形式来实现循环添加事件的效果会比闭包或自定义属性在内存空间的使用上更好一些。
PART 4
32、JSBench使用
JSbench是一个在线测试JS代码执行效率的一个网站。我们可以在浏览器中访问jsbench.me来打开相关页面:
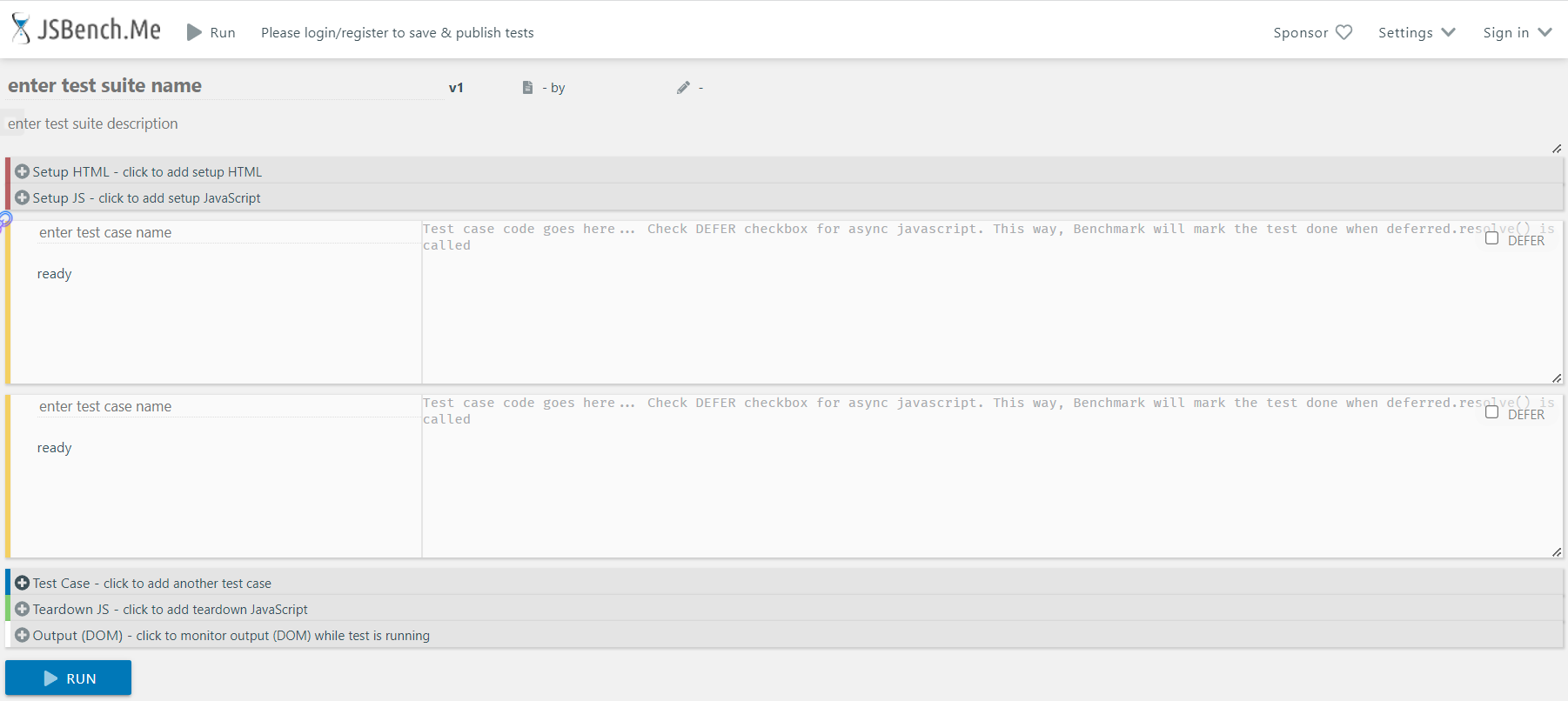
如果在测试时需要操作DOM,就可以在Setup HTML中放入DOM元素。如果测试代码有需要执行的前置操作,可以都放进Setup JS中。如果想要新增测试用例的话,可以点击Test Case进行添加,一般我们在使用时都是有两个Case用来比对两段代码的执行效率。每个case中可以添加case name来为测试的代码段起名,而case的右边则是用来输入需要测试的代码段的。其中还需要注意在case中最外层的变量名需要用var声明,否则将会找不到对应的变量。teardown JS与setup JS相对,setup是做初始化的,而teardown则是做收尾的工作。而Output dom目前暂时不需要使用,就不做介绍了。
33、变量局部化
所谓的变量局部化,就是把变量尽量放在局部作用域而非全局作用域,这样可以减少数据访问时需要查找的路径从而提高代码的执行效率。
// 假设我们需要拼接多个Dom元素
// 第一种情况。我们采用全局变量来保存保存相关数据
var i, str = ""
function packageDomGlobal() {
for(i = 0; i < 1000; i++) {
str += i
}
}
// 第二种情况。我们采用局部变量来保存保存相关数据
function packageDomLocal() {
let str = ''
for(let i = 0; i < 1000; i++) {
str += i
}
}然后在上节的jsbench.me中我们运行函数并测试相关代码的执行效率:
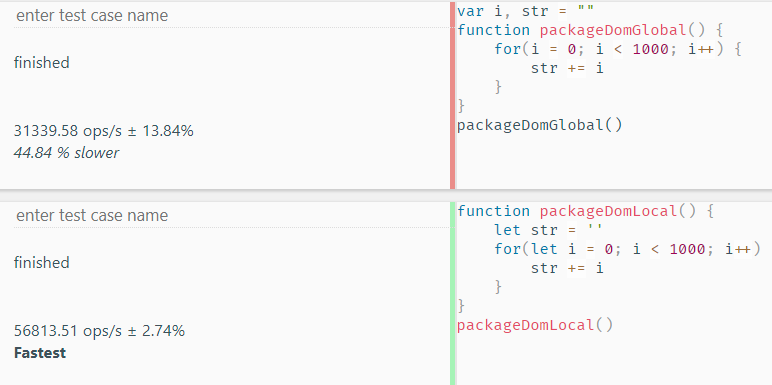
可以看到,我们采用第二种情况,即用局部变量来保存相关数据会使我们的代码执行效率更高。接下来我们来具体分析一下原因。
首先,第一种情况下,在EC(G)的VO(G)中有i,str以及packageDomGlobal,packageDomGlobal关联了对应的函数体所在堆内存地址。当packageDomGlobal开始执行,即相关EC进入执行栈后,在EC(packageDomGlobal)里,其对应的AO中找不到对应的循环变量i以及需要操作的变量str,所以需要沿着作用域链找到上层的EC(G)才能找到相关的变量,而这寻找的操作就会降低运行效率。
再看第二种情况,我们会发现EC(G)的VO(G)中只有packageDomLocal。当packageDomLocal开始执行,则会发现在EC(packageDomLocal)的AO中已经存在对应的循环变量i以及需要操作的变量str,所以可以直接使用,而不需要再去寻找从而节省时间提高效率。
总之,若我们的代码中有变量既可以放在全局作用域中,又可以放在函数私有作用域中,则尽量放在函数私用作用域里,且多层级时执行上下文离得越近则寻找的时间越少。不过一切还是需要结合实际情况来看,若有些变量实在需要共用,则放在全局下也是可以的。
34、通过缓存数据来提高代码的执行速度
在代码的编写过程中,有些数据可能会在不同的地方进行多次重复使用,这样的数据就可以提前缓存起来,后续就可以直接在缓存中获取使用,从而减少获取数据消耗的时间。
// 假设在当前页面中存在id与class均为skip的DOM元素
var oBox = document.getElementById('skip')
// 第一种情况,没有在函数体(上下文)中缓存数据
function hasClassNameNoCached(ele, cls) {
console.log(ele.className)
return ele.className == cls
}
// 调用函数
console.log(hasClassNameNoCached(oBox, 'skip'))
// 第二种情况,在函数体(上下文)中缓存数据
function hasClassNameCached(ele, cls) {
var clsName = ele.className
console.log(clsName)
return clsName == cls
}
// 调用函数
console.log(hasClassNameNoCached(oBox, 'skip'))同样,我们用jsbench.me来进行测试,不过因这里有DOM元素以及统一的获取DOM元素的JS代码,所以可以写在Setup HTML和Setup JavaScript里。
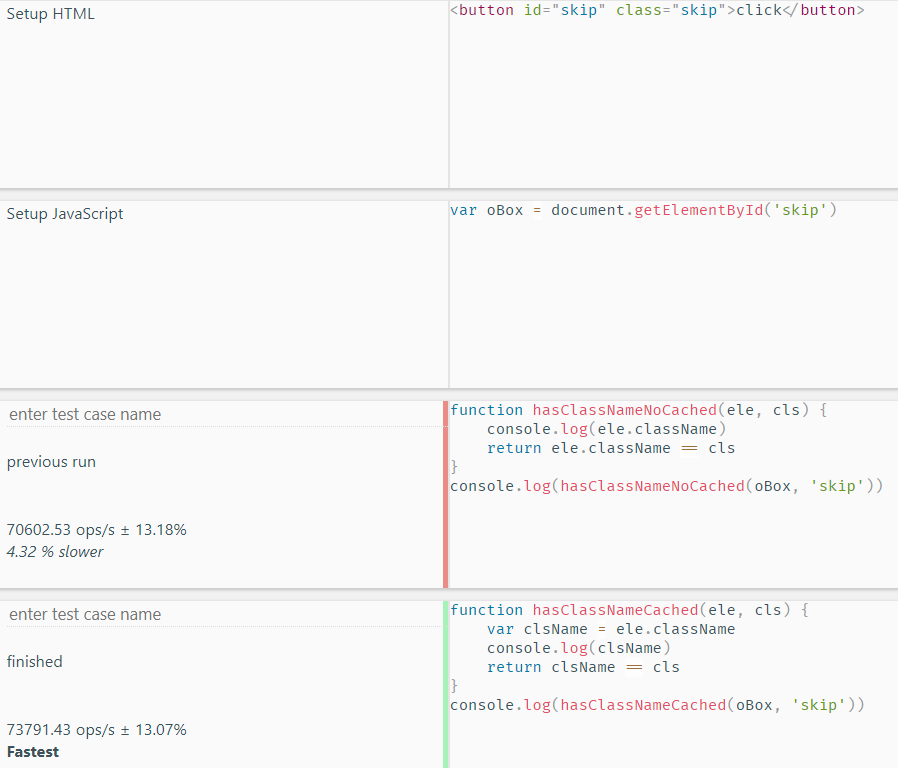
可以看到,缓存了数据的函数会运行得更快一些,原因和上一节中的变量局部化类似,因为缓存了数据之后,查找数据就不需要沿着作用域链去寻找数据,所以会让查找的时间减少从而提高代码执行效率。
而且如果我们删除了console.log部分之后,还会发现没有缓存的函数会执行得更快一些,这又是什么原因呢?这是因为我们之前提到JS代码在执行前还需要进行词法、语法分析,而缓存数据需要多声明变量,所以会在词法和语法分析上多花费一点时间。故我们也可以减少没有必要的声明和语句数来提升JS的执行效率。
35、减少访问层级
当我们用到某一个属性值时,可以通过减少访问层级来提高执行效率。
// 第一种情况,直接访问属性值
function Person1() {
this.name = 'czs';
this.age = 25;
}
let p1 = new Person1();
console.log(p1.age);
// 第二种情况,通过函数调用来获取对应属性值
function Person2() {
this.name = 'czs';
this.age = 25;
this.getAge = function() {
return this.age;
}
}
let p2 = new Person2()
console.log(p2.getAge())接下来再通过jsbench查看他们的执行速度:
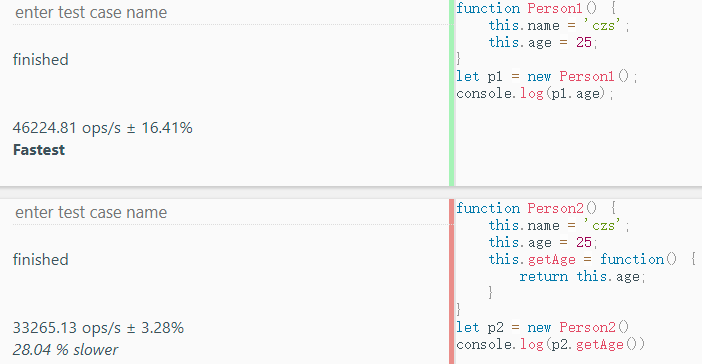
很显然,直接访问属性值比通过函数去访问属性值快很多。我们也很容易可以分析出原因,毕竟函数里就是一个独立的作用域,在其中找不到对应的变量才会沿着作用域链找,访问的层级比直接访问属性值更深一些。
36、防抖与节流
在滚动、输入的模糊匹配、点击等场景中,浏览器默认情况下都会有自己的监听事件间隔(4~6ms),如果检测到多次事件的监听执行,就会造成不必要的资源浪费。所以在一些高频率事件触发的场景下,当我们不希望对应的事件处理函数多次执行时,可以使用防抖或节流。
防抖:对于一个高频的操作而言,我们只希望识别一次,可以是第一次或最后一次(常见于输入的模糊匹配)。
节流:对于一个高频操作,我们可以自己来设置频率,让本来会执行很多次的事件触发,按我们定义的频率来执行,从而减少触发的次数(常见于点击场景)。
37、防抖函数实现
/**
* handle 最终需要执行的函数
* wait 事件触发之后多久开始执行
* immediate 控制执行第一次还是最后一次,false表示执行最后一次
*/
function myDebounce(handle, wait, immediate) {
if(typeof handle !== 'function') throw new Error('handle must be an function');
if(typeof wait === 'undefined') wait = 300; //默认wait设置为300ms
if(typeof wait === 'boolean') {
immediate = wait;
wait = 300;
}
if(typeof immediate !== 'boolean') immediate = false; //默认immediate为false
let timer = null;
return function proxy(...args) {
let self = this;
// 当immediate为true且timer为null时init才为true,
// 即若函数立即执行后,则需等待定时器把timer置空才可进行下一次
let init = immediate && !timer;
clearTimeout(timer); // 注意clearTimeout只是将系统中的定时器清除,但timer中值还在。
timer = setTimeout(() => {
timer = null;
// 当immediate为false时,只有事件不再触发wait时间后才能执行handle函数
!immediate ? handle.call(self, ...args) : null;
}, wait)
// 当init为true时立即执行handle函数
init ? handle.call(self, ...args) : null;
}
}38、节流函数实现
function myThrottle(handle, wait) {
if (typeof handle !== 'function') throw new Error('handle must be an function');
if (typeof wait === 'undefined') wait = 400; // wait默认为400ms
let previous = 0; // 用previous来保存上一次执行时的时间
let timer = null; // timer来保存定时器
return function proxy(...args) {
let now = new Date();
let self = this;
// 时间间隔interval为等待时间wait减去已经过去的时间
let interval = wait - (now - previous);
// 当时间间隔已经小于0,代表已经经过至少wait的时间了,可以执行handle。
// 注意这里还需要清空timer防止if和else if条件同时满足时设置了定时器却进入if,没办法清空。
if(interval <= 0) {
clearTimeout(timer);
timer = null;
handle.call(self, ...args);
previous = new Date();
} else if(!timer) {
// 无定时器时设置定时器使handle在interval后执行。
timer = setTimeout(() => {
clearTimeout(timer);
timer = null;
handle.call(self, ...args);
previous = new Date();
}, interval);
}
}
}39、减少判断层级
减少判断层级,就是把一些无效的条件提前return。减少判断层级嵌套可以使代码的逻辑更易理解,而且也能略微提高代码的执行效率。
// 第一种情况,判断层级深
function doSomething(part, chapter){
const parts = ['ES2016', 'Vue', 'React', 'Node'];
if(part) {
if(parts.includes(part)) {
console.log('包含内容');
if(chapter > 5){
console.log('这部分属于VIP内容');
}
}
} else {
console.log('请确认模块内容');
}
}
// 第二种情况,把无效条件提前return,减少函数嵌套
function doSomething2(part, chapter){
const parts = ['ES2016', 'Vue', 'React', 'Node']
if(!part){
console.log('请确认模块内容');
return;
}
if(!parts.includes(part)) return;
console.log('包含内容');
if(chapter > 5){
console.log('这部分属于VIP内容');
}
}再通过jsbench查看他们的执行效率:
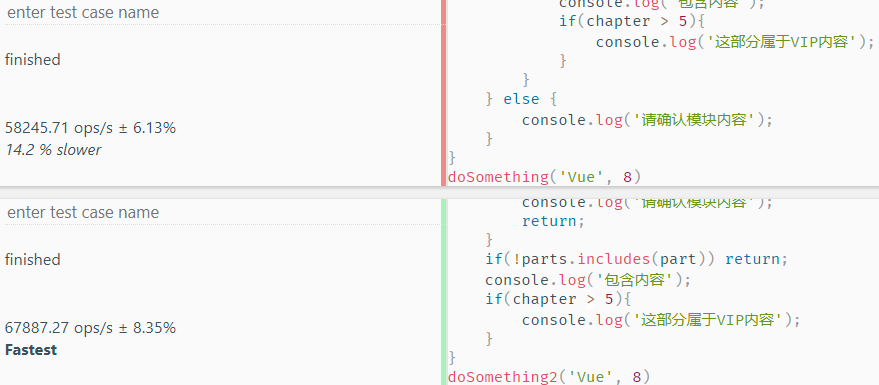
从上面可以看出第二种减少判断层级的效率会比第一种高些。因为更深的块级作用域嵌套就代表更深的作用域链,查找也需要更长时间,因此减少判断层级也可以提高代码的执行效率。
40、减少循环体活动
放在循环体里的内容往往都是我们想要重复去执行的事,当循环次数一定时,循环体里做的事情越多就意味着执行效率越慢。所以我们可以把每次循环都要用到但值不变的数据都抽离到循环体外缓存来提高代码的执行效率。
// 第一种情况,循环体中没有抽离出值不变的数据
var test = () => {
let arr = ['czs', 25, 'I love FrontEnd'];
for(let i = 0; i < arr.length; i++){
console.log(arr[i]);
}
}
// 第二种情况,循环体中抽离出值不变的数据
var test = () => {
let arr = ['czs', 25, 'I love FrontEnd'];
const length = arr.length;
for(let i = 0; i < length; i++){
console.log(arr[i]);
}
}接下来再看看他们在jsbench中测试时的效率:
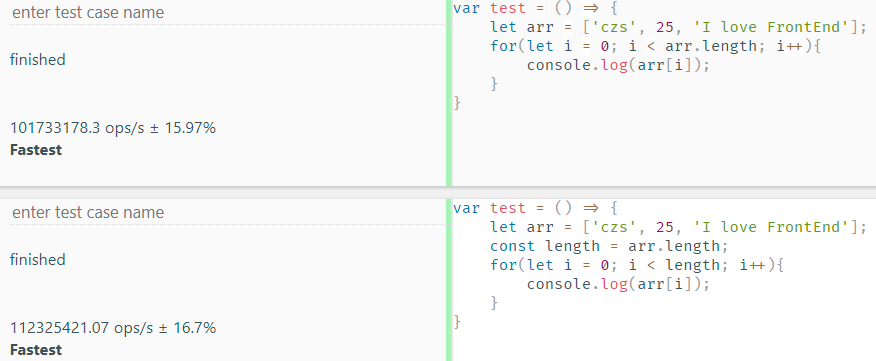
注意到虽然执行速度差不多,但减少循环体活动的方法还是略胜一筹的。
除此之外,我们还可以针对循环方式(由前到后变为由后到前循环)进行优化:
var test = () => {
const arr = ['czs', 25, 'I love FrontEnd'];
let length = arr.length;
while(length--){
console.log(arr[length])
}
}再通过jsbench与之前的代码进行测试:
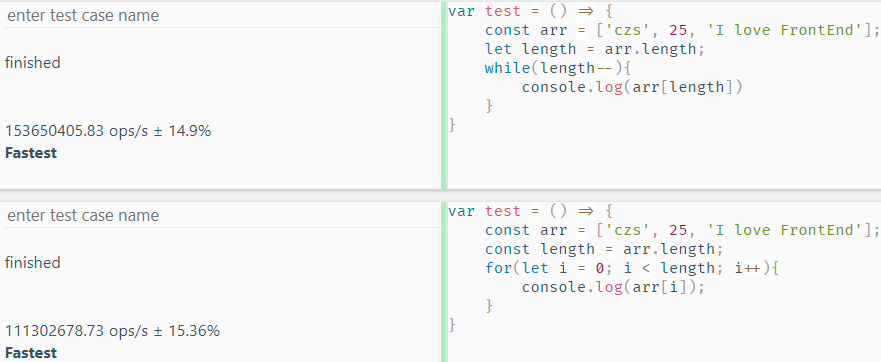
显然,通过改变了循环方式,我们让循环变得更有效率了。
41、字面量与构造式
不同的数据声明方式也会影响性能。
// 第一种方式,通过构造式声明
var test = () => {
let obj = new Object();
obj.name = 'czs';
obj.age = 25;
obj.slogan = 'I Love FrontEnd';
return obj;
}
// 第二种方式,通过字面量声明
var test = () => {
let obj = {
name: 'czs',
age: 25,
slogan: 'I Love FrontEnd'
}
return obj;
}再来看看他们的执行效率:
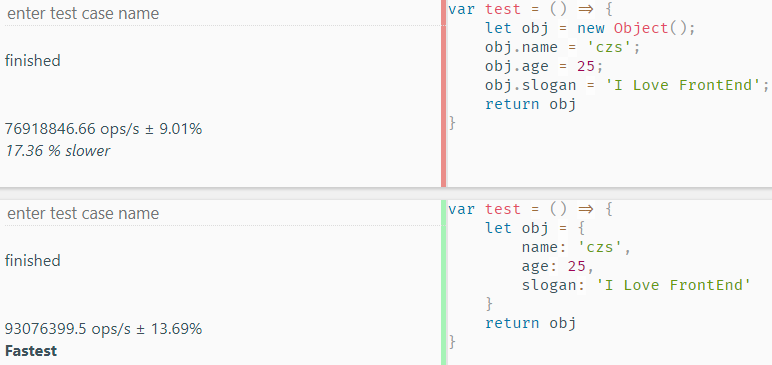
显然,通过字面量声明的方式性能更加优秀。原因也很简单,因为通过构造式声明时还会涉及到构造函数的调用,所以时间消耗也会更多些。
前面用的是引用类型,现在让我们再来看看使用基本数据类型时的情况。
var str = 'I Love FrontEnd';
var str1 = new String('I Love FrontEnd')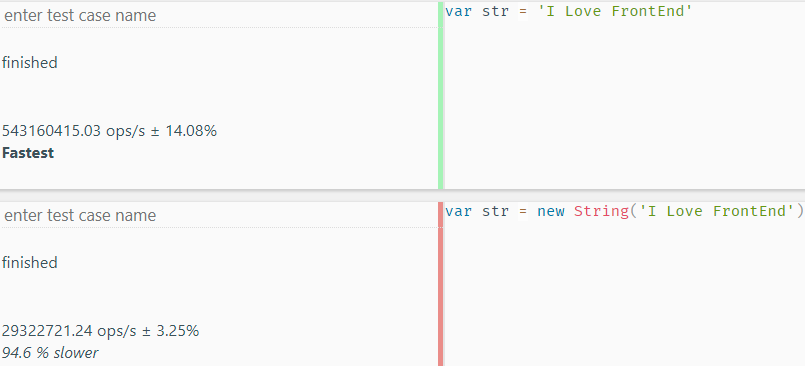
可以看出,相较于引用类型,基本数据类型的字面量创建效率远远高于构造式创建。



